Amazon Cognito Multi-Region Replication: Keep Users Logged In Through a Regional Outage
For a lot of online businesses, the single most expensive thing that can happen is not a slow page or a missing feature. It is users being unable to log in. When authentication goes down, your whole product goes dark at once, support tickets spike, and the outage is visible to every customer at the same moment. If your sign-in runs on Amazon Cognito in a single AWS Region, that Region has quietly been a single point of failure for your entire business. In June 2026 AWS closed that gap. Amazon Cognito now supports multi-Region replication, so your users, their credentials, and your pool configuration can be mirrored to a standby Region and authentication can keep working even if your primary Region has a bad day.
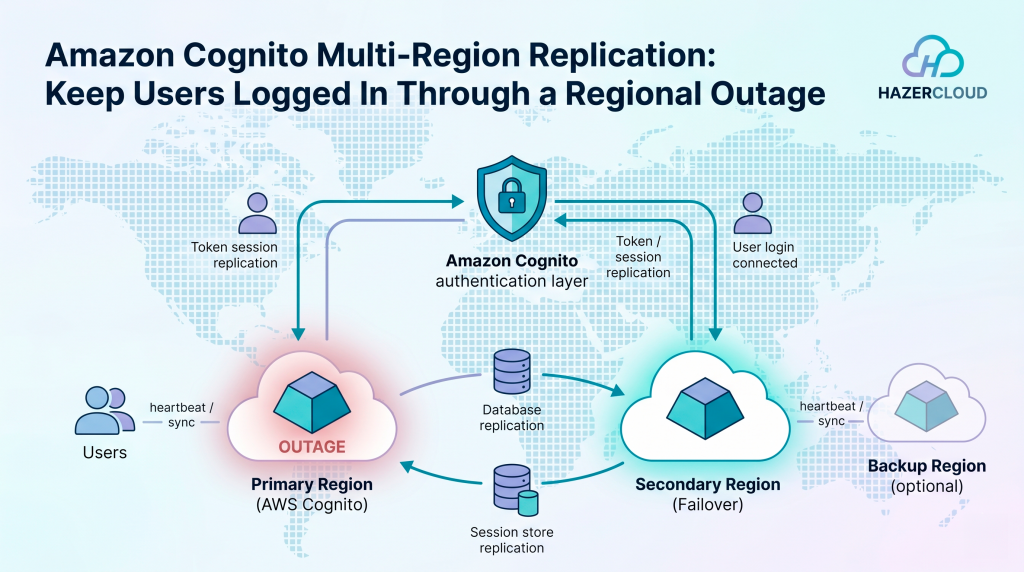
In plain terms, here is what it does. You nominate a primary Cognito user pool and a secondary user pool in another Region, and Cognito replicates user profiles, machine identities, credentials, federation setup, and pool configuration from primary to secondary in near real-time. The secondary pool sits in read-only standby. If the primary Region is disrupted, you redirect authentication traffic to the secondary pool, and users who were signed in stay signed in while registered users can log in again with their existing credentials. No mass password reset, no rebuilding your user directory under pressure. It is a one-directional copy, so during a failover you keep authentication available, but actions that write data, like new sign-ups and profile changes, are paused until the primary recovers.
Why Single-Region Cognito Was a Hidden Risk
Most teams that adopted Cognito did so because it took authentication off their plate. You get a managed user directory, sign-in flows, multi-factor authentication, and federation without running any of it yourself. The trade-off, until now, was that the whole thing lived in one Region. You could make your application servers and your database highly available across Availability Zones, you could even run active-passive across Regions for your compute and data, and still have your login layer pinned to a single Region with no clean way to fail it over.
That mattered because authentication is upstream of everything. If users cannot get a valid token, it does not help that your API tier and database are healthy in a second Region. The front door is locked. Teams that took resilience seriously knew this and either accepted the risk, built fragile homegrown replication by exporting users on a schedule, or moved off Cognito entirely for a self-managed identity provider they could run in two Regions. None of those were good options for a growing business that just wanted reliable login without a dedicated identity team. Native replication removes the awkward choice.
How the Failover Actually Works
The design is deliberately simple, and understanding it helps you set expectations with the rest of the business. Replication flows one way, from the primary Region to the secondary. The secondary pool is read-only while the primary is healthy, which keeps the model easy to reason about and avoids the conflicts you get when two Regions both accept writes. Because credentials and user data are kept in sync continuously, the secondary is ready to serve sign-ins the moment you point traffic at it.
During a failover you get authentication, not full functionality. Users who already hold valid sessions continue without interruption, and users who need to sign in can do so with the credentials they already have. What you do not get while running on the secondary is the write path. New user registration and profile updates are unavailable until the primary Region is back. For most businesses that is an acceptable trade during an outage, because keeping existing customers able to use the product is far more valuable than accepting brand new sign-ups during the same window. The important thing is to decide that in advance and tell your support and product teams what to expect, rather than discovering it mid-incident.
What You Need to Set It Up
There are a couple of prerequisites worth knowing before you plan this. First, you must configure a multi-Region customer managed key in AWS Key Management Service to encrypt user data at rest across both Regions. That is a sensible security requirement, but it does mean key management is part of the setup rather than an afterthought, so involve whoever owns your KMS strategy. Second, multi-Region replication is an add-on available on the Cognito Essentials and Plus feature tiers, so it carries a cost and is not part of the bare Lite tier. You will want to weigh that ongoing cost against what an authentication outage would actually cost your business in lost revenue and reputation.
On Region coverage, the feature is available across the Regions that matter most for UK, European, and North American businesses, including London, Ireland, Frankfurt, Paris, and Stockholm in Europe, several US East and US West Regions, Canada Central, São Paulo, and a spread of Asia Pacific Regions. So a UK business can keep its primary in London and stand up a secondary in Ireland or Frankfurt, which also keeps user data within Europe for data residency purposes.
Where This Fits in Your Resilience Plan
It is worth being clear about what this does and does not solve. Multi-Region replication makes your identity layer resilient, which has historically been the hardest piece to make highly available. It does not, on its own, make your whole application multi-Region. For a real failover to work, your application tier and your data stores also need to be reachable from the secondary Region, and your traffic routing, usually through Route 53 or your load balancing layer, needs to be able to shift users over. Cognito replication is the missing puzzle piece that makes a multi-Region story actually complete, but it is one piece of several.
The right way to think about it is as the part that used to force a compromise. Before, you could build everything else for two Regions and still be stuck at the login screen. Now the login screen can move with the rest of your stack, which means a regional outage becomes a routing decision rather than a business-ending event.
What to Do About It
Start by deciding whether login is a revenue-critical path for your business, because if it is, this should move up your priority list. If you are already on the Cognito Essentials or Plus tier, scope the work to set up a multi-Region KMS key, create a secondary user pool in a sensible standby Region, and enable replication. Then, and this is the part teams skip, actually rehearse the failover. Document the runbook for redirecting traffic to the secondary pool, test it in a controlled window, and make sure your team knows that new sign-ups and profile edits pause during a failover so support can set customer expectations. Treat it as a drill you repeat, not a box you tick once.
If you want help deciding whether this is worth the add-on cost for your situation, or you would rather have someone design and test the failover with you, HAZERCLOUD can help. We build and prove out resilient AWS architectures for growing UK, US, and European businesses, including identity, data, and traffic failover, so an outage in one Region does not take your product offline. Book a free consultation and resilience assessment at https://hazercloud.com/contact/ and we will help you find the single points of failure before they find you.